Tensorflow ve Keras ile Yeni Ba??layanlar i??in ??rnek Bir Model Geli??tirme ve E??itim
Yapay zeka ve makine ????renmesinin g??n??m??zde her alanda kullan??lmas??ndan dolay?? her sekt??rden ??al????an??n bir ??ekilde bu konu hakk??nda fikir sahibi olmas?? gerekti??ini d??????n??yorum. Bu yaz??mda basit anlamda bir veri seti nas??l okunabilir formata getirilir. Sinirsel bir a?? nas??l tasarlan??r ve e??itim nas??l yap??labilir? Gibi sorular??n cevaplar??n?? vermeye ??al????t??m. Bunu g??sterirken de g??n??m??zde pop??ler olan derin ????renme ve kullan??lan bir ??er??eve olan Tensorflow 2 ve Keras ile g??stermeye ??al????t??m. Yine bulut ??zerinde ??rne??in Google bulut ile Tensorflow 2 ve Keras kullanarak modelleri geli??tirebilirsiniz. Bilgisayar??n??za da kurabilece??iniz Tensorflow 2 ve Keras yard??m??yla ayn?? i??lemleri yapabilirsiniz. E??itimin uzun s??rebilece??i durumlarda CPU yerine g????l?? bir ekran kart?? i??lemcisini kullanabilirsiniz. Bu ??rnekte UCI veri setleri sitesinden indirece??imiz ??stanbul Menkul K??ymetler Borsas?? veri setini YSA???ya ????retmeye ??al????aca????z.
https://archive.ics.uci.edu/ml/datasets/ISTANBUL+STOCK+EXCHANGE#
Bu veri setini bu ??rnek model i??in biraz d??zenledim ve girdi ile ????kt?? bilgileri a??a????daki gibi toparlam???? oldum.
| Girdiler SP: STANDARD & POOR’S 500 ENDEKS?? DAX: Almanya borsa endeksi FTSE: ??ngiltere borsa endeksi NIK: Japonya borsa endeksi BVSP: Brezilya borsa endeksi EU: Avrupa endeksi EM:?? Geli??mekte olan piyasalar endeksi | ????kt?? ??stanbul Menkul K??ymetler Borsas?? Ulusal 100 Endeksi |
Model ????kt?? olarak ??stanbul 100 endeksinin art??p azalmas??n?? tahmin etmeye ??al????acak. Dolay??s??yla veri setindeki ????kt?? i??in 0 olmas?? endeksin d????ece??i 1 olmas?? ise y??kselece??i anlam??na gelmektedir.
Veri setinin normalize edilmi?? son halini bu linkten indirebilirsiniz.
Bilgisayar??n??zda kullanaca????m??z ??er??evelerin y??kl?? oldu??unu varsayarsak, Spyder program??n?? a????p modeli olu??turmaya ba??layabiliriz.
??nce gerekli k??t??phaneleri ekliyoruz. Bu k??t??phaneleri k??saca ??zetlersek tensorflow temel k??t??phanesi, ??ok boyutlu veriler ??zerinde i??lemler yapabilmek i??in numpy k??t??phanesi veri setini okuyabilmek ad??na pandas k??t??phanesi model geli??tirme ve gizli katmanlar?? olu??turmak i??in Sequential ve Dense k??t??phaneleri.
import tensorflow as tf
import numpy as np
import pandas as pd
from keras.models import Sequential
from keras.layers import Dense ??nce haz??r veri setini web linkinden okuyup dosyay?? temsil edecek de??i??kene at??yoruz.
csv_dosya = tf.keras.utils.get_file('Stock_Istanbul.csv','http://www.fatihadak.com.tr/upload/datasets/Stock_Istanbul.csv')
df=pd.read_csv(csv_dosya)E??itim i??in hi??bir zaman veri setinin tamam?? kullan??lmaz. Sinirsel a????n ????renip ????renmedi??ini anlayabilmek i??in ayn?? veri seti i??erisinden daha ??nce kendisine g??stermedi??imiz veri seti ile test etmemiz gerekir. Veri setini %70 e??itim %30 test i??in rastgele ay??rmak i??in,
msk=np.random.rand(len(df)) < 0.7
egitim = df[msk]
test=df[~msk]B??ylelikle e??itim veri setinin %70???i e??itim isimli de??i??kende %30???u ise test isimli de??i??kende olacakt??r. Bu veri setlerini ??ok boyutlu diziler olarak i??lem yapabilmek ad??na numpy t??r??ne ??eviriyoruz.
egtVeriSeti = egitim.to_numpy()
tstVeriSeti = test.to_numpy()Veri setinde girdi ve ????kt??lar?? de??i??kenler ile temsil etmek i??in a??a????daki gibi atama yap??yoruz.
inp = egtVeriSeti[:,0:7]
out = egtVeriSeti[:,7]
inptest = tstVeriSeti[:,0:7]
outtest = tstVeriSeti[:,7]Modelimize 8 adet s??tun bulunmaktayd?? 7???si girdi ve bir adet ????kt?? olarak de??i??kenlere atam???? olduk.
Yapay sinir a???? modelini olu??turmaya ba??l??yoruz.
model = Sequential()Yapay sinir a????m??za 3 adet gizli katman eklemek istiyoruz. Derin ????renme tensorflow ??er??evesinde bunlar Dense olarak isimlendirilmekte.
model.add(Dense(15, input_dim=7, activation='relu'))
model.add(Dense(7, activation='relu'))
model.add(Dense(1, activation='sigmoid'))??lk gizli katmanda 15 adet n??ron bulunuyor ve relu aktivasyon fonksiyonu kullan??l??yor. ??kinci gizli katmanda 7 adet n??ron bulunuyor ve yine ayn?? aktivasyon fonksiyonu kullan??l??yor. ??????nc?? gizli katmanda 1 adet n??ron bulunmakta ve sigmoid aktivasyon fonksiyonu kullan??l??yor. E??itim i??lemine ge??meden modelimizi derlememiz gerekiyor.
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])E??itimi ba??latmak i??in fit fonksiyonunu ??a????r??yoruz. Burada 100 epoch ??al????aca????n?? belirtiyoruz. 1 epoch e??itim veri setinin tamam?? okutuldu??unda tamamlan??r. Parametre olarak e??itim veri setinin girdi ve ????kt??lar?? veriyoruz.
model.fit(inp, out, epochs=100, batch_size=5)Buradaki batch_size parametresine de??inmek gerekirse bir epoch???ta ka?? adet ??rne??in a????rl??klar g??ncellenmeden ??nce dikkate al??nmas?? gerekti??ini belirtir.?? Buradaki ??rnekte 5 sat??r veri olarak ayarlanm????t??r. E??itim a??a????daki ??ekildeki gibi ba??lay??p epoch baz??nda bilgi verip sonlanacakt??r. Her epoch???ta do??rulu??un ve kayb??n nas??l de??i??ti??i takip edilebilir.
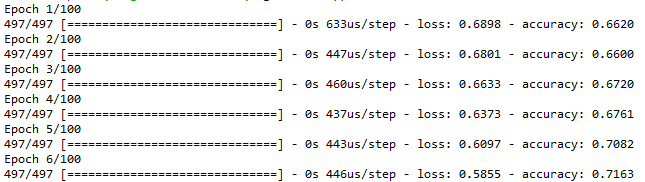
E??itim tamamland??ktan sonra test verisi ile e??itilmi?? a???? test etmemiz gerekir. E??itim veri setinde elde etti??imiz do??ruluk 1 ??zerinden 0,72 iken test i??in kontrol etmek ad??na a??a????daki kodlar?? ??al????t??r??yoruz.
_, dogruluk = model.evaluate(inptest, outtest)
print('Dogruluk: %.2f' % (dogruluk*100))Dikkat edilirse evaluate fonksiyonuna test veri setindeki girdi ve ????kt??lar verilmi??tir. Bu ??rnek i??in 0,67 gibi bir do??ruluk elde edildi??i g??r??lebilir.